이 글의 원문은 StackLLaMA: A hands-on guide to train LLaMA with RLHF입니다
ChatGPT, GPT-4, Claude와 같은 모델들은 인간 피드백에 의한 강화 학습(RLHF)이라고 하는 방법을 통해 우리가 원하고 사용하려는 방식에 잘 맞게 파인튜닝된 강력한 언어모델입니다
이 블로그 포스트에서는, 우리는 아래 기술을 조합해 RLHF와 Stack Exchange의 질문/답 데이터를 가지고 LLaMA모델 학습을 진행한 내용을 설명합니다.
- 슈퍼바이즈드 파인튜닝 Supervised Fine-tuning (SFT)
- 보상-선호 모델링 Reward / preference modeling (RM)
- 인간 피드백에 의한 강화 학습 Reinforcement Learning from Human Feedback (RLHF)

우리는 이러한 접근방식을 조합하여 StackLLaMA모델을 출시합니다. 이 모델은 🤗 Hub에서 사용할 수 있으며(원래 LLaMA모델은 Meta의 LLaMA릴리즈 참조) 전체적인 학습 파이프라인은 허깅페이스 TRL라이브러리의 일부로 사용할 수 있습니다. 우선 모델이 무엇을 할 수 있는지 맛보기 위해서, 아래의 의 데모를 사용해 보세요
데모 (https://huggingface.co/spaces/trl-lib/stack-llama)
LLaMA모델
RLHF를 수행할 때, 성능이 좋은 모델로 시작하는 것이 중요합니다. RLHF단계는 단지 우리가 모델과 상호작용하는 방식, 모델과의 응답방식을 서로 맞추기 위한 파인튜닝단계일 뿐입니다.
따라서 우리는 최근에 발표된 고성능의 LLaMA모델을 사용하기로 결정했습니다. LLaMA모델은 Meta AI에서 개발한 최신의 거대 언어모델입니다. LLaMA는 7B부터 65B 매개변수 크기별로 제공되고, 1T에서 1.4T 토큰으로 훈련되어 성능이 매우 좋습니다. 우리는 아래의 단계를 진행하는데 7B모델을 베이스로 사용하였습니다. 모델을 구하려면, Meta AI의 양식을 사용하세요
Stack Exchange 데이터셋
사람의 피드백을 수집하는 것은 매우 복잡하고 비용이 많이 드는 작업입니다. 쓸만한 모델을 만들면서 이 예제의 프로세스를 부트스트랩 하기 위해, 우리는 StackExchange데이터셋을 사용합니다. 데이터셋은 StackExchange플랫폼에 있는 질문과 그에 대한 답변(코드 및 그 외의 여러 항목에 대한 StackOverflow 포함)으로 구성되어 있습니다. 이 데이터는 승인된 답변의 라벨 및 찬성 개수가 함께 제공되기 때문에 이번 사례 적합한 데이터입니다.
우리는 Askell et al.2021에 설명된 방식을 따라 각각의 답변에 점수를 매겼습니다.
score = log2 (1 + upvotes)는 가장 가까운 정수로 반올림합니다. 채택된 답변일 경우 1점을 더합니다 (부정적으로 추천된 경우 -1점을 할당합니다)
보상 모델의 경우, 나중에 살펴보겠지만 비교할 질문당 항상 두 개의 답변이 필요합니다. 어떤 질문은 수십 개의 답변이 있어 가능한 답변 쌍이 많습니다. 점수를 제한하기 위해 질문당 최대 10개의 답변 쌍으로 샘플링했습니다. 마지막으로 모델의 출력을 좀 더 읽기 쉽게 하기 위해 HTML을 Markdown형태로 변환하여 포맷을 정리했습니다. 여기에서 데이터셋과 프로세싱 노트북을 확인할 수 있습니다
효율적인 학습 전략
가장 작은 LLaMA모델 학습에도 엄청난 양의 메모리가 필요합니다. 간단히 계산해 보면 bf16에서 모든 파라미터는 사용하고 있는 8byte 외에 추가적으로 2byte(fp32에서는 4byte)를 사용합니다. Adam Optimizer와 같은 것들이 그렇습니다(자세한 내용은 Transformers의 성능 문서를 참고하세요). 따라서 7B파라미터 모델은 (2+8)*7B=70GB의 메모리가 필요하고 Attention score와 같은 중간값을 계산할 때는 더 필요할 수 있습니다. 때문에 80GB A100 장비 하나만으로는 학습할 수 없습니다. half-precision학습과 같이 효율적인 최적화 하도록 약간의 편법을 사용하면 메모리를 조금 아낄 수 있지만, 금세 메모리는 부족해질 것입니다.
또 다른 방법은 8bit로 로드된 모델에 대해 Low-Rank Adaptation(LoRA)를 수행할 수 있는 peft라이브러리와 같이 파라미터 효율 최적화 튜닝(PEFT) 기술을 사용하는 것입니다
모델을 8bit로 로딩하면 매개변수당 1바이트만 필요하므로 메모리 사용량이 크게 줄어듭니다 (예를 들어, 7B LLaMA는 7GB 메모리를 사용). 원래의 가중치로 직접 학습하는 대신, LoRA는 작은 adapter레이어를 일부 특정레이어(일반적으로 attention레이어) 위에 추가합니다. 그러므로, 학습 가능한 매개변수는 크게 줄어듭니다
이 시나리오에서는, 전체 파인튜닝설정에 맞춰 10억 매개변수당 1.2~1.4GB(배치 사이즈와 시퀀스 길이에 따라 다르지만) 정도로 합니다. 위에 첨부된 블로그 포스트에 자세히 설명된 대로, 이렇게 하면 거대 모델(NVIDIA A100 80GB 같은 경우 50-60B규모의 모델) 파인튜닝을 저렴하게 할 수 있습니다
이러한 기술을 통해 거대 모델 파인튜닝을 사용자 장비 또는 Google Colab에서 수행할 수 있습니다. 주목할만한 데모로는 facebook/opt-6.7b(float16에서 13GB) 파인튜닝이나, Google Colab에서 OpenAI/Wiseper-large 등이 있습니다. peft사용에 대해 좀 더 알아보기 위해서는 우리의 github repo나 이전 블로그 포스트(https://huggingface.co/blog/trl-peft) 내용 중 사용자 장비에서 20b매개변수 모델 학습에 대한 내용을 참고해 주세요
이제 우리는 거대 모델을 1개의 GPU에서 학습할 수 있습니다. 하지만 학습은 여전히 매우 느립니다. 이럴 때 가장 단순한 전략은 데이터 병렬처리입니다. 동일한 학습 설정을 별도의 GPU에 복제하고 각 GPU에 서로 다른 배치를 실행합니다. 이를 통해 모델의 forward/backward pass를 병렬화하고 GPU 개수에 따라 확장할 수 있습니다.
우리는 torchrun이나 accelerate launch를 통해 스크립트를 호출할 때, 간단하게 argument를 전달하는 것으로 코드 변경 없이 병렬처리를 지원하는 transformers.Trainer 또는 accellerate를 둘 다 사용합니다. 다음은 accelerate와 torchrun을 각각 사용해 1대의 장비에 8개의 GPU로 학습하는 스크립트입니다
accelerate launch --multi_gpu --num_machines 1 --num_processes 8 my_accelerate_script.py
torchrun --nnodes 1 --nproc_per_node 8 my_torch_script.py슈퍼바이즈드 파인튜닝 Supervised fine-tuning
보상모델 학습하고 RL을 이용해 우리의 모델로 튜닝을 시작하기 전에 관심이 있는 도메인에서 모델이 이미 잘 작동한다면 도움이 됩니다. 우리의 경우, 질문에 대한 답변이 잘 나오기를 원하지만 다른 사례에서는 특정 명령을 따르기를 원할수도 있는데, 이 경우 인스트럭션 튜닝이 좋은 아이디어입니다. 이를 달성하는 가장 쉬운 방법은 도메인이나 태스크의 텍스트를 기반으로 모델링하려는 목표를 위해 지속적으로 훈련하는 것입니다. StackExchange데이터셋은 방대하기 때문에(1000만 개 이상의 인스트럭션) 그 하위 집합을 이용하여 쉽게 언어모델을 학습할 수 있습니다.
RLHF를 수행하기 전에 수행하는 파인튜닝은 그리 특별한 것은 아니며, 우리가 여기에 적용하는 것과 같이 사전학습된 인과적 언어모델의 목적입니다. 데이터를 효율적으로 사용하기 위해 우리는 packing이라는 기술을 사용합니다. 배치작업에서 하나의 샘플에 하나의 텍스트를 넣고 가장 긴 텍스트나 모델의 최대 콘텍스트를 패딩 하는 대신, 우리는 많은 텍스트를 EOS토큰과 연결하고 콘텍스트 크기의 청크를 잘라 패딩 없이 배치를 채웁니다
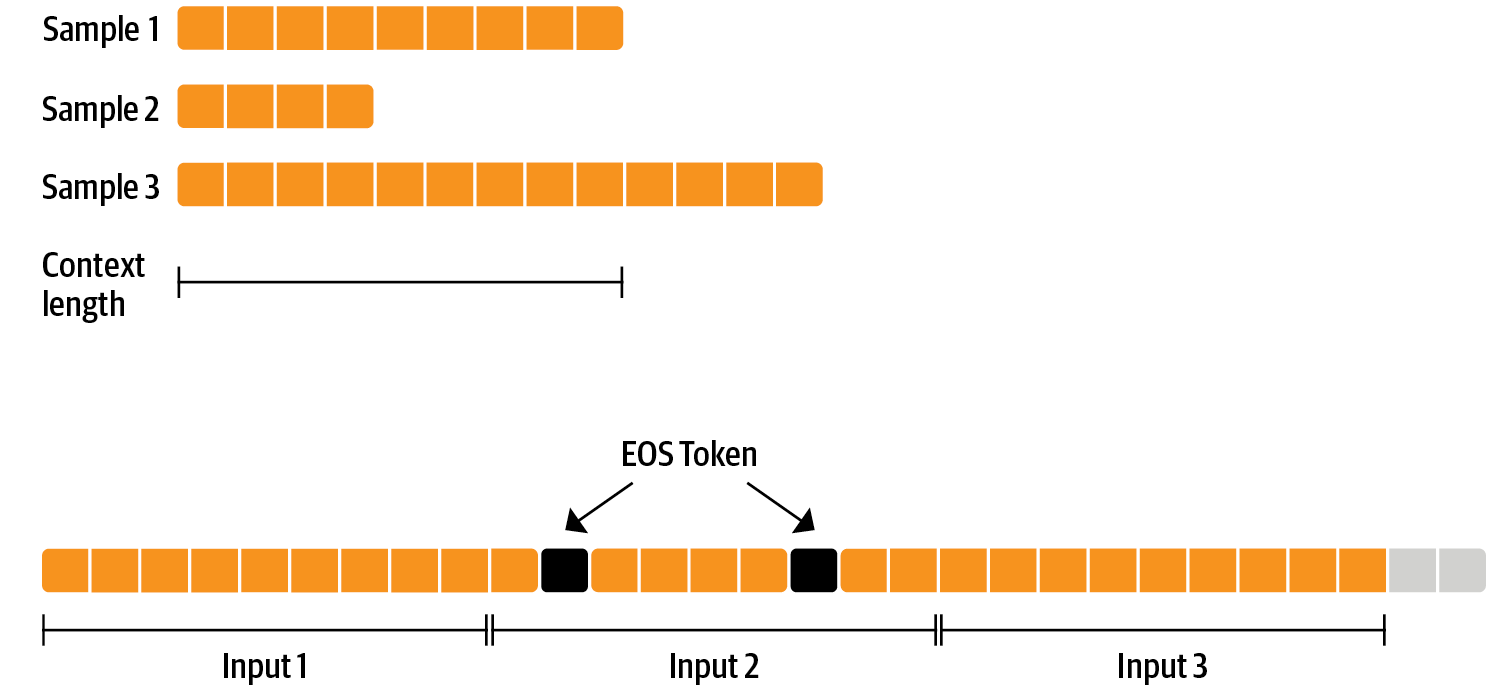
학습에 대한 이런 접근은 일반적으로 손실로 마스킹되는 패딩 토큰과 달리 모델을 통과하는 각각의 토큰 역시 훈련되므로 보다 효율적입니다. 만일 데이터가 많지 않고 간혹 콘텍스트 오버플로우로 잘리는 토큰이 걱정된다면 기존 데이터 로더를 사용할 수도 있습니다.
패킹은 ConstantLengthDataset로 처리하고 모델을 peft로 로드한 뒤 Trainer를 사용할 수 있습니다. 우선 모델을 int8로 로딩하고, 학습 준비를 한 다음, LoRA어댑터를 추가합니다.
# load model in 8bit
model = AutoModelForCausalLM.from_pretrained(
args.model_path,
load_in_8bit=True,
device_map={"": Accelerator().local_process_index}
)
model = prepare_model_for_int8_training(model)
# add LoRA to model
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)우리는 인과적 언어모델의 목적에 따라 수천 단계에 걸쳐 모델을 학습하고 저장합니다. 이후에 우리는 다른 목적을 위해 모델을 다시 튜닝하고, 원래 모델 가중치와 Adapter 가중치를 병합합니다.
면책조항: LLaMA라이선스로 인해 우리는 다음 섹션에서 adapter가중치와 모델 체크포인트만 공개합니다. 베이스 모델의 가중치에 접근을 신청하려면 Meta AI의 양식을 작성하고 다음의 스크립트를 실행하여 Transformer형식으로 변환하면 됩니다. 또한 v4.28이 출시될 때까지 소스에서 Transformer 설치가 필요하다는 점에 유의하세요
이제 태스크를 위해 모델을 파인튜닝했고, 보상 모델을 훈련할 준비가 되었습니다.
보상 모델링과 인간 선호도
원칙적으로 우리는 사람의 주석을 통해 RLHF를 직접적으로 적용하여 모델을 파인튜닝 할 수도 있습니다. 하지만 이렇게 하려면 각각의 최적화를 반복한 후에 평가 샘플을 사람에게 보내야 합니다. 이런 방법은 학습 샘플의 수는 많은데 사람이 직접 읽고 주석처리하는 시간이 오래 걸리기 때문에 비용이 많이 듭니다.
이러한 직접적인 피드백을 대신하기 좋은 방법은 RL루프 전에 수집된 사람의 주석에 대한 보상 모델을 학습시키는 것입니다. 보상모델의 목표는 사람이 텍스트를 평가하는 방식을 모방하는 것입니다. 보상 모델을 만드는 데는 몇 가지 전략이 있습니다. 가장 간단한 방법은 주석을 예측(예를 들어 평가 결과를 좋음/나쁨의 두 가지로)하는 것입니다
실제로는 보상모델은 주어진 프롬프트 x에 대해 후보 (yk,yj)를 제시한 결과와 사람이 어떤 것을 더 높게 평가할지 예측한 결과 두 결과의 순위를 예측하는 것이 더 잘 작동 합니다.
이는 다음과 같은 손실 함수로 변환될 수 있습니다.
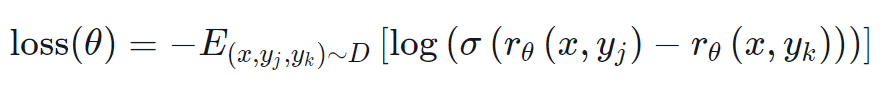
StackExchange 데이터셋을 사용하면 우리는 점수를 기반으로 두 답변에 대한 사용자의 선호도를 추론할 수 있습니다. 이러한 정보와 위에서 정의한 손실을 사용하여 우리는 커스텀 손실 함수를 추가하여 Transformer.Trainer를 수정할 수 있습니다.
class RewardTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
if return_outputs:
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
return loss우리는 10만 쌍의 후보 서브셋을 활용하고 5만개의 보류된 세트로 평가합니다. 보통의 학습 배치 사이즈인 4로 우리는 bf16정밀도의 Adam optimizer를 사용한 단일 에포크에 LoRA peft adaptor를 사용하여 LLaMA모델을 학습합니다. 우리의 LoRA설정은 다음과 같습니다.
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)학습은 가중치&편향을 통해 기록되며, 🤗 연구 클러스터에 있는 8개의 A100 GPU를 사용해 수 시간이 걸려 최종 정확도 67%를 달성햇습니다. 별로 높은 점수 같지는 않겠지만, 이 작업은 사람이 주석을 적는다고 해도 어려운 일입니다.
다음 섹션에서 자세하게 설명하겠지만, 결과 adapter는 고정 모델에 병합될 수 있고 추후 다운스트림에서 사용하도록 저장 할 수 있습니다.
사람 피드백에 의한 강화 학습
파인튜닝된 언어모델과 보상 모델이 준비되었으므로, 이제 RL루프를 시작할 준비가 되었습니다. 이 작업은 대략 다음 3단계로 진행됩니다.
1. 프롬프트에서 응답 생성
2. 보상모델을 사용하여 응답 평가
3. 평가에 따라 강화학습 정책 최적화 단계를 실행
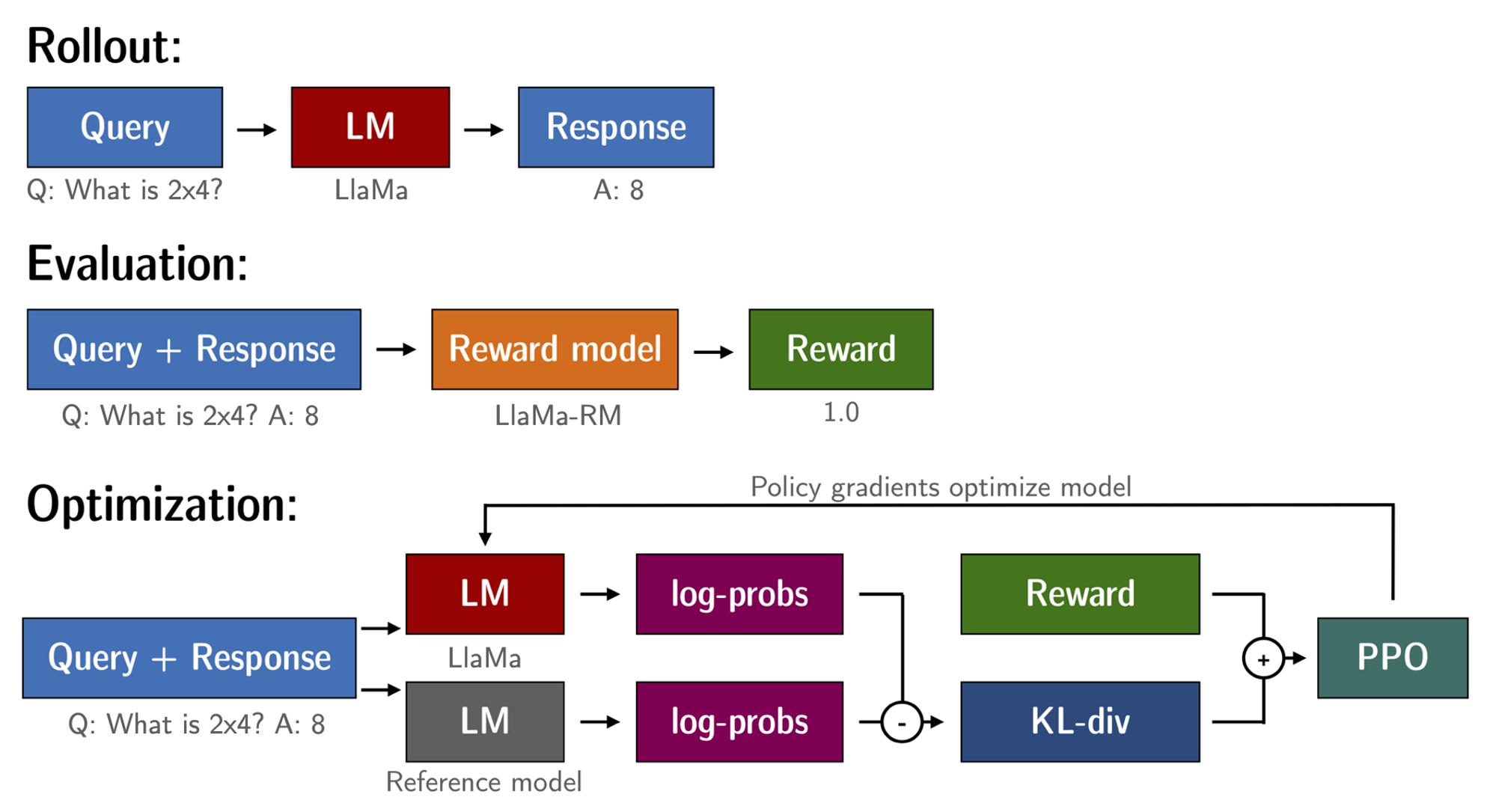
쿼리와 응답 프롬프트는 토큰화되어 모델에 전달되기 전에 다음과 같이 템플릿화 됩니다.
Question: <Query>
Answer: <Response>동일한 템플릿이 SFT, RM, RLHF단계에도 사용되었습니다.
RL로 언어모델을 학습할때 흔히 발생하는 문제는 모델이 완전한 횡설수설을 만드는 식으로 보상모델을 악용하도록 학습하여 보상 모델이 높은 보상을 받게 된다는 것입니다. 이러한 균형을 맞추기 위해 우리는 보상에 패널티를 추가합니다. 훈련하지 않은 모델을 레퍼런스로 유지하고 KL-divergence를 계산하여 새로운 모델의 생성 결과와 비교합니다.
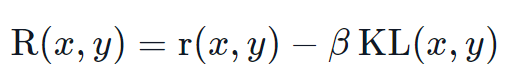
여기서 r은 보상모델의 보상이고 KL(x,y)는 현재의 정책과 참조 모델간의 KL-devergence 입니다.
또한 메모리 효율적인 학습을 위해 peft를 활용하는데, 이는 RLHF컨텍스트에 추가적인 이점이 있습니다. 여기 참조 모델과 정책은 동일한 베이스인 SFT모델 공유하며, 8bit로 로드하고 훈련중에 고정됩니다. 베이스 모델의 가중치를 공유하면서 PPO를 사용하여 정책의 LoRA가중치를 독점적으로 최적화 합니다.
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
question_tensors = batch["input_ids"]
# sample from the policy and generate responses
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
length_sampler=output_length_sampler,
**generation_kwargs,
)
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# Compute sentiment score
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]
# Run PPO step
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
# Log stats to WandB
ppo_trainer.log_stats(stats, batch, rewards)우리는 🤗 연구 클러스터의 3x8 A100-80G GPU로 20시간동안 학습했습니다만, 여러분은 훨씬 더 빠르게(8개의 A100 GPU에서 20시간 미만) 괜찮은 결과를 얻을 수 있습니다. 모든 훈련에 대한 통계는 가중치&편향 에서 확인할 수 있습니다.
그렇다면, 학습한 모델은 무엇을 할 수 있을까요? 한번 살펴봅시다!
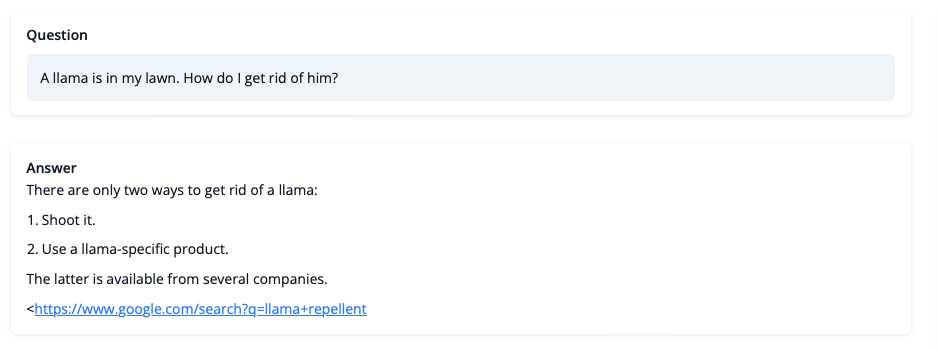
LLaMA가 대답하는 문제에 대한 답을 그대로 믿을수는 없지만, 답변은 일관성 있어 보이며 Google링크까지 제공합니다. 다음으로 학습에 대해 남은 과제 몇 가지를 확인하겠습니다.
남은 과제, 불안정성 및 해결 방법
RL로 LLM을 훈련하는 것은 항상 순조롭지는 않습니다. 오늘 데모하는 모델은 수 많은 실험과 실패, hyperparamter sweep의 결과물입니다. 그럼에도 불구하고 이 모델은 완벽하지 않습니다. 여기서는 이 예제를 만드는 동안 겪은 몇 가지 주의사항과 골칫거리를 공유하겠습니다.
높은 보상은 높은 성과를 의미할까요?
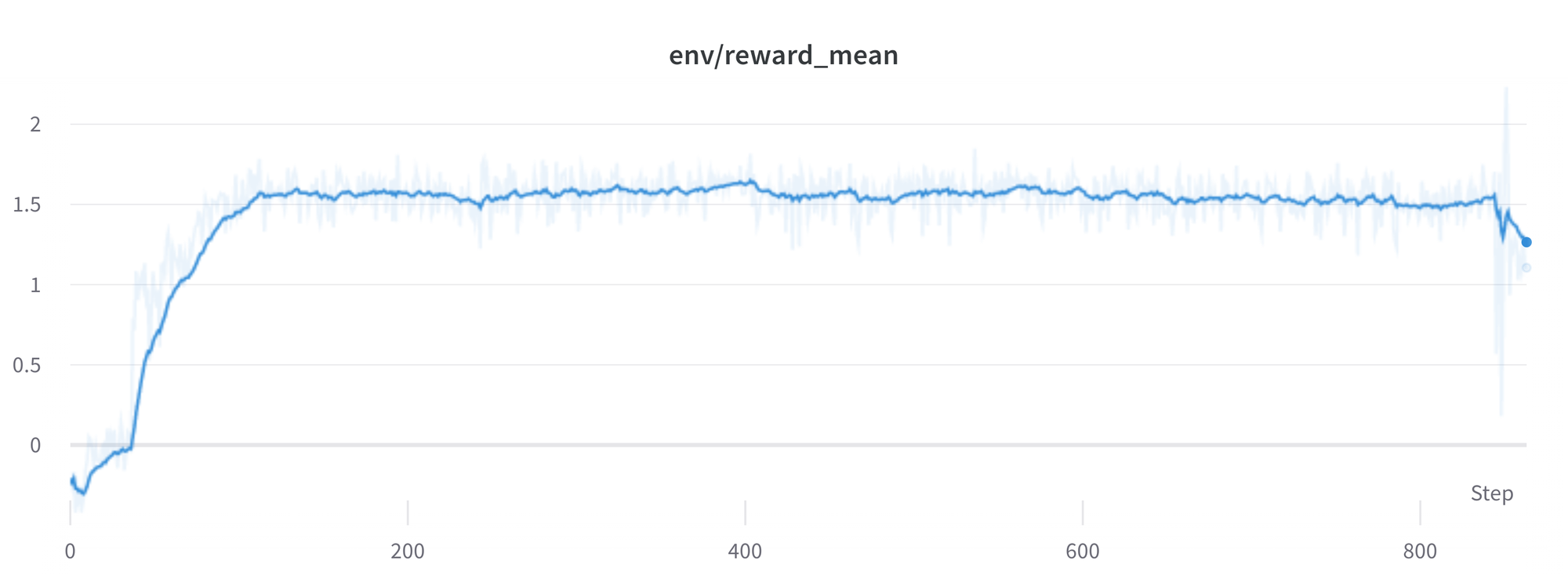
일반적으로 RL에서는 가장 높은 보상을 받기를 원합니다. RLHF에서 사용하는 보상모델은 완벽하지 않으며 기회만 있으면 PPO알고리즘은 이러한 불완전성을 악용합니다. 이는 갑작스럽게 보상이 증가하는 것으로 나타나는데, 정책을 통해 생성된 텍스트를 보면 대부분 문자열 ```을 포함하고 있습니다. 이는 보상 모델이 코드 블럭이 포함된 stack exchange답변을 그렇지 않은 답변보다 일반적으로 더 높은 순위를 매기기 때문입니다. 다행히 이 문제는 매우 드물게 관찰되었으며, 일반적으로 KL패널티로 이러한 악용에 대응할 수 있습니다.
KL은 항상 양수 값이지 않나요?
앞에서 언급했듯, KL페널티 조건은 모델의 출력이 기본 정책에 근접할 수 있도록 유지시키기 위해 사용됩니다. 일반적으로 KL 발산은 두 분포사이의 거리를 측정하며, 항상 양수 입니다. 그러나 trl에서 우리는 실제 KL분포와 동일할 것으로 예상되는 KL근사치를 사용합니다.
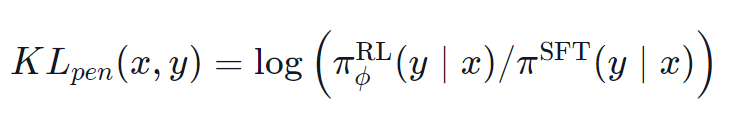
분명히, SFT모델보다 낮은 확률을 가지는 정책에서 토큰을 샘플링 했을 때 KL페널티는 음수가 됩니다. 하지만 정책에서 제대로 샘플링 되지는 않을 것이므로 평균값은 양수가 됩니다. 그러나 어떤 생성 전략은 몇몇 토큰들을 강제로 생성하거나 억제할 수 있습니다. 예를들어 배치로 생성할 때 완료된 시퀀스가 패딩 되고 최소길이를 설정할 때 EOS 토큰은 억제됩니다. 모델은 음수 KL로 이어지는 토큰에 아주 높거나 늦은 확률을 할당할 수 있습니다. PPO알고리즘이 보상을 위한 최적적화를 수행하면서, 그러한 음수 페널치를 따라 불안정성을 초래할 수 있습니다.
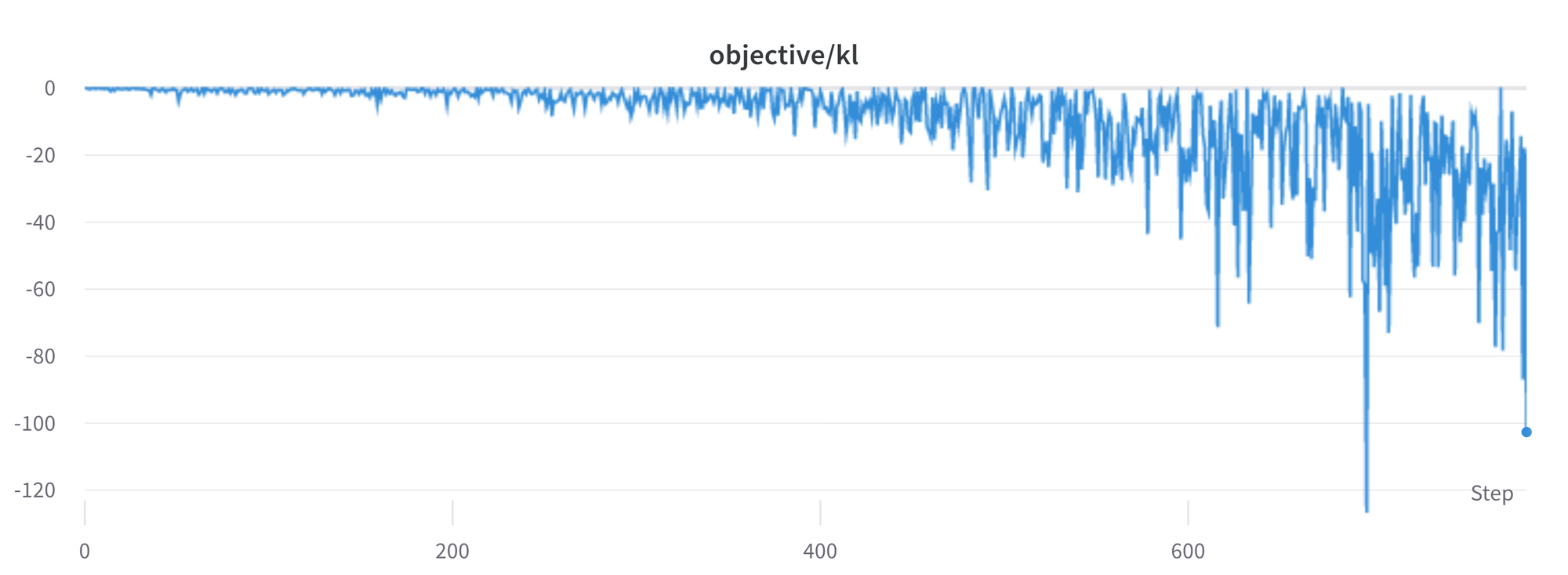
응답을 생성할떄는 신중해야 하며 우리는 보다 정교한 생성 방법에 의지하기 전에 항상 간단한 샘플링 전략을 사용할 것을 권장합니다.
진행중인 문제
아직 우리가 더 잘 이해해야 하고 해결해야 하는 문제가 많이 남아있습니다. 예를들어 때때로 손실이 급증하여 불안정성을 초래할 수 있습니다.
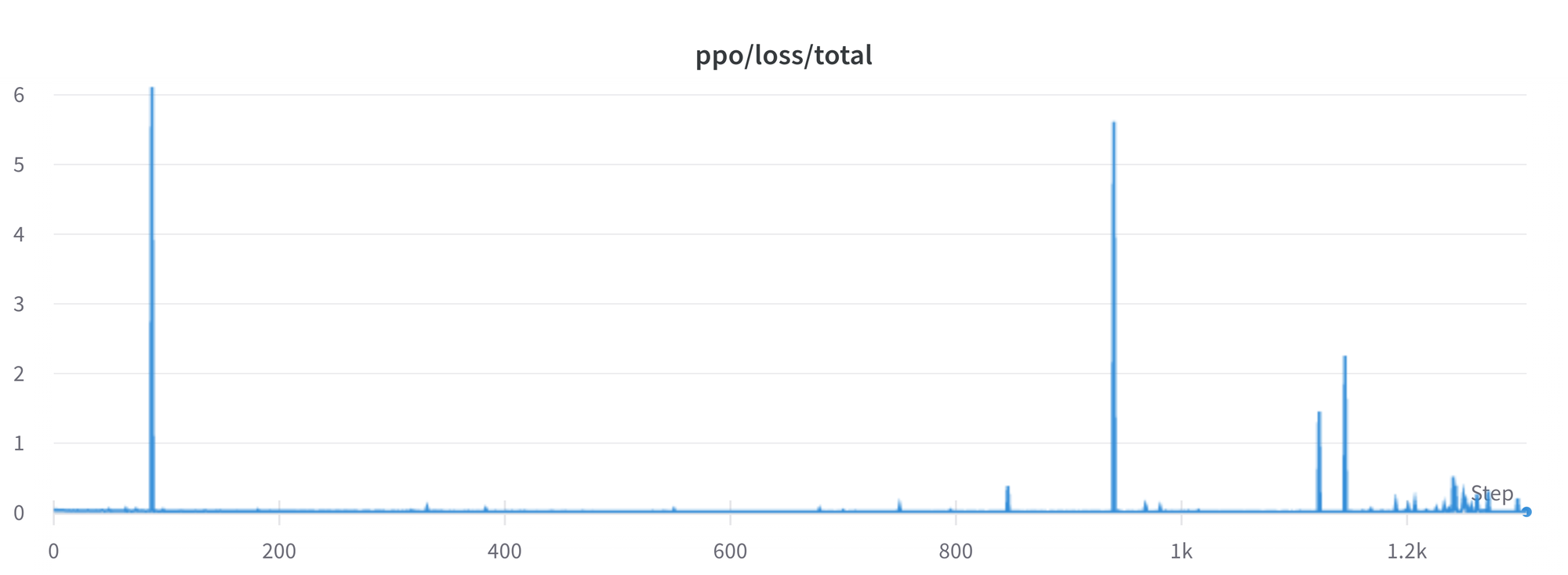
우리는 이러한 문제를 파악하고 해결해 가면서, 커뮤니티에 도움이 될 수 있도록 trl변경사항을 업스트림 할 것입니다.
결론
이 포스트에서 우리는 RLHF에 대한 전체 학습 주기를 알아보았습니다. 사람이 주석을 단 데이터셋을 준비하는 것에서 시작하여 언어 모델을 도메인 최적화 하고 보상 모델을 학습하고, 마지막으로 RL을 사용하여 모델을 학습했습니다.
peft를 사용하여 누구나 우리의 예제를 단일 GPU에서 실행할 수 있습니다! 만약 학습이 너무 느리다면, 코드 변경없이 데이터를 병렬처리하고 GPU를 더 추가하여 학습을 확장할 수 있습니다.
실제 사례에서는 이것은 단지 첫 단계에 불과합니다. 모델을 학습하면, 반드시 모델을 평가하고 다른모델과 비교하여 얼마나 우수한지 확인해야 합니다. 이 작업은 보상 데이터셋을 구성하는 작업과 유사하게 다른 여러 모델의 버전의 세대별 순위를 매겨서 수행할 수 있습니다
평가 단계를 추가하면 모델을 개선할 수 있는 방법이 있는지 알아보기 위해 데이터셋과 학습 설정을 반복하는 것과 같은 재미있는 일이 시작됩니다. 다른 데이터셋을 추가하거나 기존 데이터셋에 더 좋은 필터를 적용할 수 도 있습니다. 반면 보상 모델에 대해 다른 규모와 아키텍처를 적용하거나 더 오래 학습할수도 있습니다.
우리는 RLHF와 관련된 단계를 개선하기 위해 적극적으로 TRL을 개선할 것이며 사람들이 이를통해 무엇을 구축할지 기대됩니다!. 기여에 관심이 있으시다면 GitHub이슈를 확인해 보세요.
인용
@misc {beeching2023stackllama,
author = { Edward Beeching and
Younes Belkada and
Kashif Rasul and
Lewis Tunstall and
Leandro von Werra and
Nazneen Rajani and
Nathan Lambert
},
title = { StackLLaMA: An RL Fine-tuned LLaMA Model for Stack Exchange Question and Answering },
year = 2023,
url = { https://huggingface.co/blog/stackllama },
doi = { 10.57967/hf/0513 },
publisher = { Hugging Face Blog }
감사의 말
데모의 기반이된 멋진 스트리밍 텍스트 생성 데모를 공유해 주신 Philipp Schmid에게 감사 드립니다. 또한 게시물의 초안에 대해 귀중하고도 상세한 피드백을 제공해 주신 Omar Sanseviero 와 Louis Castricato에게도 감사 드립니다.
'글쓰기' 카테고리의 다른 글
| LangChain을 이용한 비즈니스 어플리케이션을 고민하다 (0) | 2023.04.28 |
|---|---|
| LLM에 Stable Diffusion Moment가 온다 - 2 (0) | 2023.04.09 |
| LLM에 Stable Diffusion Moment가 온다 - 1 (0) | 2023.04.08 |
| 리디, 2022년 매출 2,211억 달성 상세내용 분석 (0) | 2023.04.05 |
| 애플의 ARM CPU도입이 기대되는 이유 (0) | 2020.06.24 |



